

- This event has passed.
2023 PESA WEBINAR SERIES: Machine Learning and Intelligent Augmentation Applied to Legacy Subsurface Data
Kindly supported by Rock Flow dynamics 
This live webinar will take place at:
11am – Perth
12.30pm – Darwin, Adelaide
1pm – Brisbane, Canberra, Hobart, Melbourne, Sydney
Use the calendar link on this page to add this event in to your own calendar at the correct local time for your location.
Tickets are free for members (please log in to see this) and $10 for non members.
Please buy your tickets and immediately follow the link in the ticket e-mail (not the calendar invite or this webpage, which is just generic and not event specific) to set up your registration with the webinar software well in advance of the time of the talk. Once registered with the webinar software you will receive a reminder e-mail 1 hour beforehand.
Machine Learning and Intelligent Augmentation Applied to Legacy Subsurface Data
Presented by Jess Kozman (Katalyst Data Management)
Abstract
Recent emphasis on low carbon energy projects in Australia means large volumes of unstructured subsurface data become valuable to operators. . The need to evaluate reservoirs for energy or carbon storage or light gas extraction means a requirement to de-risk geographic search and make machine-readable text available for advanced data science algorithms. Companies with access to data gain a competitive advantage in licensing activities. Exisiting data management workflows may be too costly and resource intensive to support these emerging requirements.
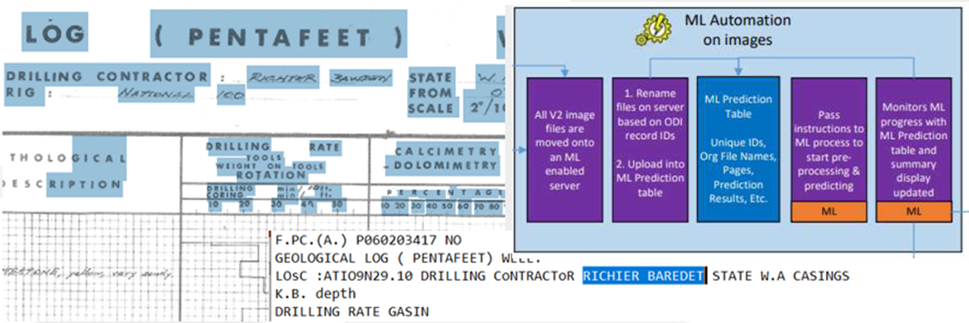
We highlight how a workflow using Machine Learning (ML) and Intelligence Augmentation (IA) can improve the efficiency of a typical data management workflow. Our example involves manually identifying relevant well logs in images from collection of tens of thousands of file types, a typical task for an operator using open-file data in Australia. The current process may involve downloading from multiple state and federal repositories and manually entering indexing metadata into internal data repositories.
We have developed internal ML/AI data extraction workflows that that streamline automatically separating well log image files, extracting mandatory indexing meta-data, and presenting model-trained choices to end-users for adjustment and verification. The full solution involves image classification, enhanced Optical Character Recognition(OCR), Natural Language Processing (NLP) for keyword labels and values, and a User Interface (UI) that delivers and documents increased data quality and confidence metrics.
Related Events
-
Monday, 27 July @ 5:30 pm - 7:30 pm (Australia/Adelaide time)
 SA/NT
SA/NT -
Wednesday, 29 July @ 11:30 am - Thursday, 30 July @ 4:00 pm (Australia/Brisbane time)
QLD
-
Thursday, 30 July @ 5:00 pm - 7:30 pm (Australia/Brisbane time)
 QLD
QLD